
티스토리 뷰
1. CBOW : Continuous Bag-of-Words Model
CBOW 모델은 주변 단어를 이용해서 가운데 있는 misssing word를 predict 하는 Neural Network이고, 이 모델의 by-product로 word embedding vector가 생성된다.

문장을 window size 5로 train 한다고 하면 가운데 있는 단어를 양 옆 두개의 단어를 기준으로 prediction하는 모델이다.
"I am ? becasue I" 에서 ?에 들어갈 단어를 찾아야 하는 것이다. 즉, X가 context word, Y가 center word로 아래의 표와 같이 train set을 생성할 수 있다.

context vector를 하나의 single vector로 만들기 위해서는 각 단어들을 one-hot vector로 변환하고 이 one-hot vector들의 평균을 구해서 문장(context words)의 vector를 생성한다.
각 단어별 one-hot embedding이 다음과 같다고 했을때,
- am : [1,0,0,0,0]
- because : [0,1,0,0,0]
- happy : [0,0,1,0,0]
- I : [0,0,0,1,0]
- leanring : [0,0,0,0,1]
위의 예제 문장에서 context words는 다음과 같은 순서로 변환된다.
I am becasue I -> [[0,0,0,1,0], [1,0,0,0,0], [0,1,0,0,0],[0,0,0,1,0]] -> [0.25, 0.25, 0, 0.5, 0]
- context words: I am because I
- context words vector : [0.25,0.25,0,0.5,0]
- center word : happy
- conter word vector : [0,0,1,0,0]
context vector인 [0.25, 0.25, 0, 0.5, 0]를 input으로 하고 center word인 because의 vecotor [0,1,0,0,0] 를 output으로 하는 Neural network의 weight와 bias를 train하는 것이 CBOW모델이고, 그 과정에서 생성되는 부산물인 wieght값을 이용해 word embedding을 생성할 수 있다.
2. CBOW model의 Architecture

예제) I am happy because I am learning
- V = 5 (unique한 단어 개수)
- V_dim = 1 (embedding vector dimension, 하이퍼파라미터)
- N = 3 (hidden layer dimension, 하이퍼파라미터)
각 vector size는 아래와 같다.
- x = (5, 1)
- W1 = (3, 5), b1 = (3,1)
- W2 = (5, 3), b2 = (5,1)
- y_hat = (5, 1)
3. Extracting Word Embedding Vectors
어떻게 by-product로 word embedding vector를 얻을 수 있을까?
1) w1를 사용하기
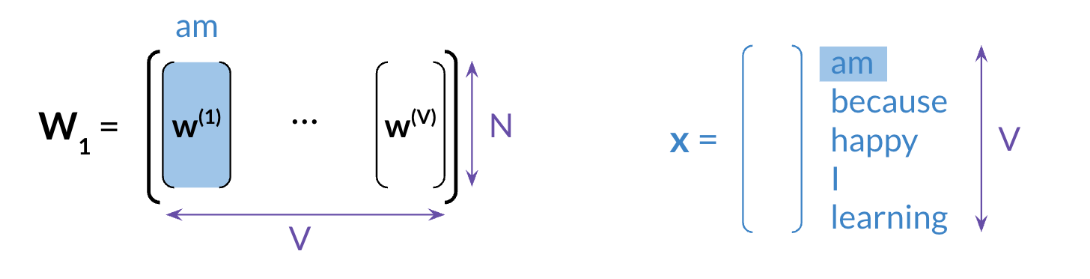
2) w2를 사용하기
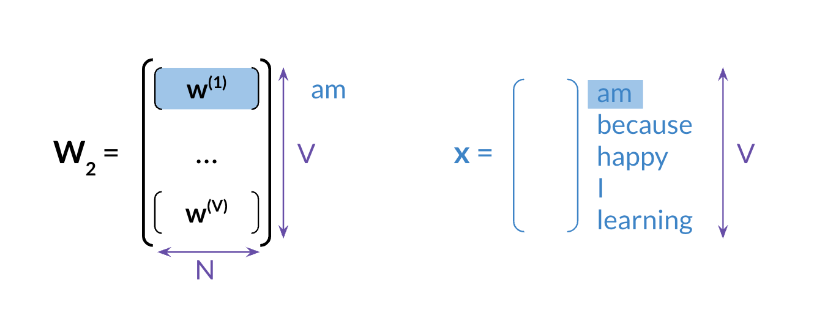
3) w1, w2를 평균내서 사용하기
- intrinsic evaluation / extrinsic evaluation을 통해 1~3중 어느 방법이 좋은지 평가해볼 수 있다
4. Word Embedding Vector 평가 방법
1) intrinsic evaluation
모델 내에서 자신의 성능을 수치화하여 내놓는 내부평가
- analogies : sementic analogies(의미적 정확성), syntactic analogies(문법적 정확성) 을 기준으로 평가한다.
- 예) Fraince-Paries, Korea-Seoul / Was-am, were-are
- clustering : 유사한 단어끼리 clustering 되는가?
- visualization : 시각화, 유사한 단어들이 가까이 위치하는가?
2) extrinsic evaluation
외부 모델을 기준으로 평가
- word embedding을 사용해서 external task(named entity recognition, speech tagging 등)를 수행해보고 성능을 평가한다.
- 임베딩이 실제로 얼마나 유용한지 평가할 수 있지만 intrinsic evaluation보다 시간이 더 걸리고 troubleshoot이 더 어려울 수 있다는 단점이 있다.
참고자료
'NLP' 카테고리의 다른 글
| huggingface Transformer 학습 시 생성되는 checkpoint (1) | 2024.04.01 |
|---|---|
| tokenizer train (0) | 2024.03.29 |
| huggingface repository create / delete / clone / push (0) | 2024.03.28 |
| [NLP] gensim Word2Vec을 이용한 embedding vector train (0) | 2023.03.26 |